如何优化 Solidity 智能合约中��的燃气费
本指南提供了一个实用的分步指南,介绍如何在 Solidity 中编写智能合约时优化气体成本。
为什么气体优化很重要?
气体优化是智能合约开发的关键部分。 它有助于确保智能合约即使在网络高度拥堵的情况下也能保持高效和成本效益。 通过减少合约执行的计算开销,开发人员可以降低交易费用,加快确认时间,并提高其 dApp 的整体可扩展性。
对于开发人员来说,气体优化就是编写简洁、安全和可预测的代码,尽量减少不必要的计算。 对于用户来说,这关系到确保他们能在不支付过高费用的情况下与您的合同进行互动。
为什么对 Kaia 尤为重要
目前,Kaia 区块链已推出超过 83 款 Mini dApp,成为交易量领先的 EVM 兼容链,这主要得益于这些链上应用的爆炸式增长。
每个 Mini dApp 都依赖智能合约来执行链上操作。 无论是铸造物品、下注还是管理游戏中的资产,每一次合同互动都会消耗气体。 如果不进行优化,这些应用程序很快就会变得过于昂贵,用户无法与之互动,尤其是在大规模互动时。
这就是为什么燃气效率不仅仅是一个 "可有可无 "的东西。 这是必须的。 在 Kaia 基础上开发的开发人员必须确保对每个函数调用进行优化,以最大限度地降低成本,同时保持功能性和安全性��。
气体优化技术
存储包装
在区块链上存储和检索数据是最耗气的操作之一,尤其是当数据必须跨交易和区块持续存在时。 在 Solidity 中,这些数据存储在合同存储器中,这是永久性的,会产生气体成本。 为了降低这些成本,开发人员必须仔细优化存储的使用方式,尤其是在声明状态变量时。
Kaia 虚拟机(KVM)将合同数据存储在称为存储槽的单元中。 每个存储槽可容纳 256 位(32 字节)数据。 Solidity 数据类型有不同大小,例如,bool 为 1 字节,地址为 20 字节。
通过一种称为 "存储打包 "的技术,我们可以将较小的变量紧密地排列在一个 32 字节的存储槽中。 这有助于减少气体用量,因为从一个存储槽读取或写入气体的成本要比访问多个存储槽低得多。
让我们来看看下面这个例子:
分解:
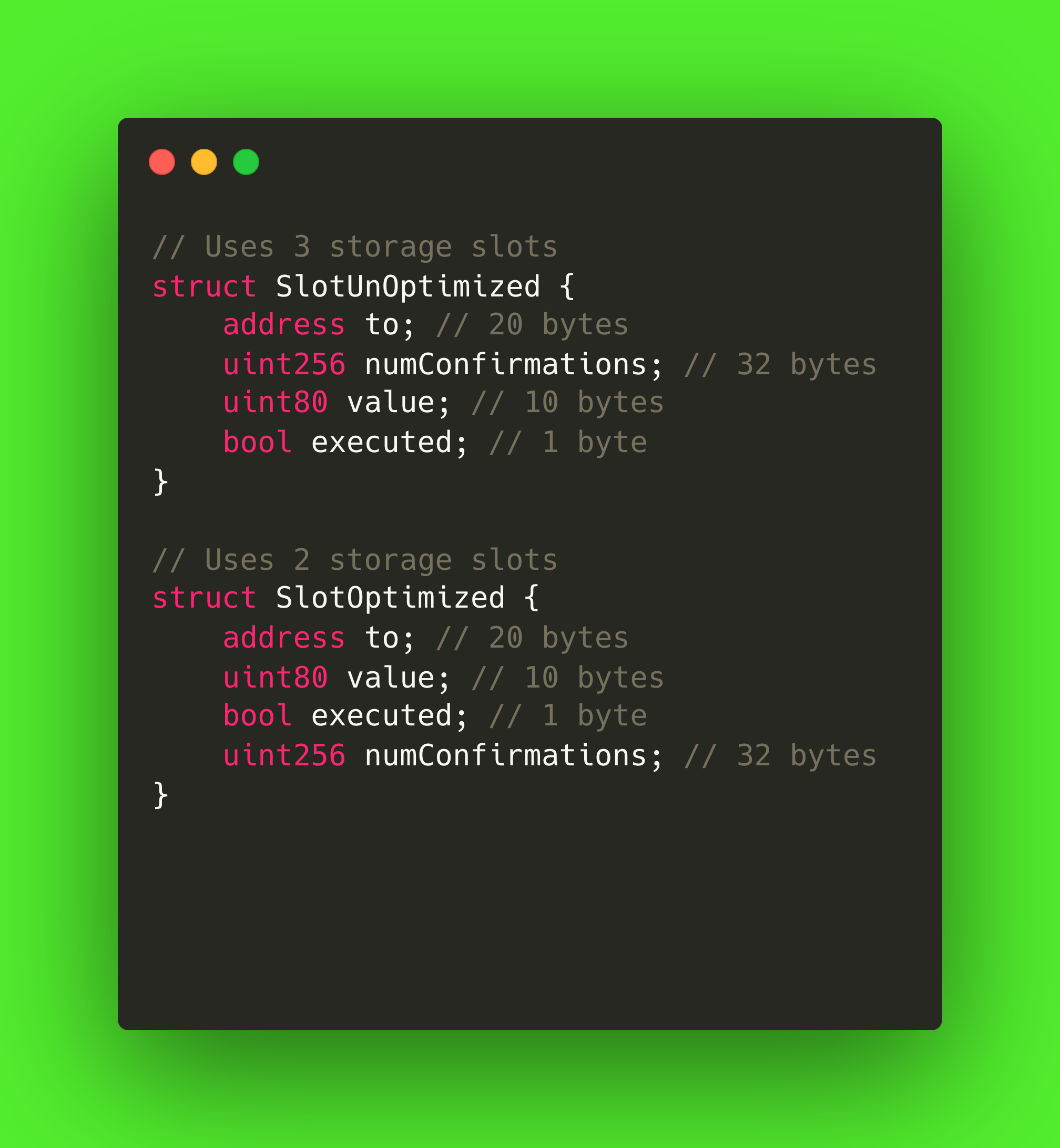
在未优化版本(SlotUnOptimized)中,Solidity 会这样存储结构:
- 地址至 -> 占用 20 个字节 -> 存储在 0 号插槽中
- uint256 numConfirmations -> 占用 32 个字节 -> 保存在 1 号插槽中
- uint80 值(10 个字节)和执行的 bool(1 个字节) -> 存储在第 2 个插槽中
尽管value和executed变量很小,但由于对齐填充的原因,除非明确地重新排序,否则Solidity会将它们放在各自的存储槽中。 因此,该结构使用 3 个储气槽,这意味着储气操作的天然气成本是原来的 3 倍。 但是,"地址(20 字节)+ uint80(10 字节)+ bool(1 字节)"的总大小为 31字节,在单槽的 32字节限制之内。 只需对声明重新排序,将较小的变量集中在一起,Solidity 就能将它们打包到同一个槽中。 这就是仓储包装的精髓。
如上图所示,在优化版本(SlotOptimized)中,所有较小的变量都相邻放置,这样编译器就能将它们存储在较少的槽中,从而降低部署和运行时的气体成本。
缓存存储
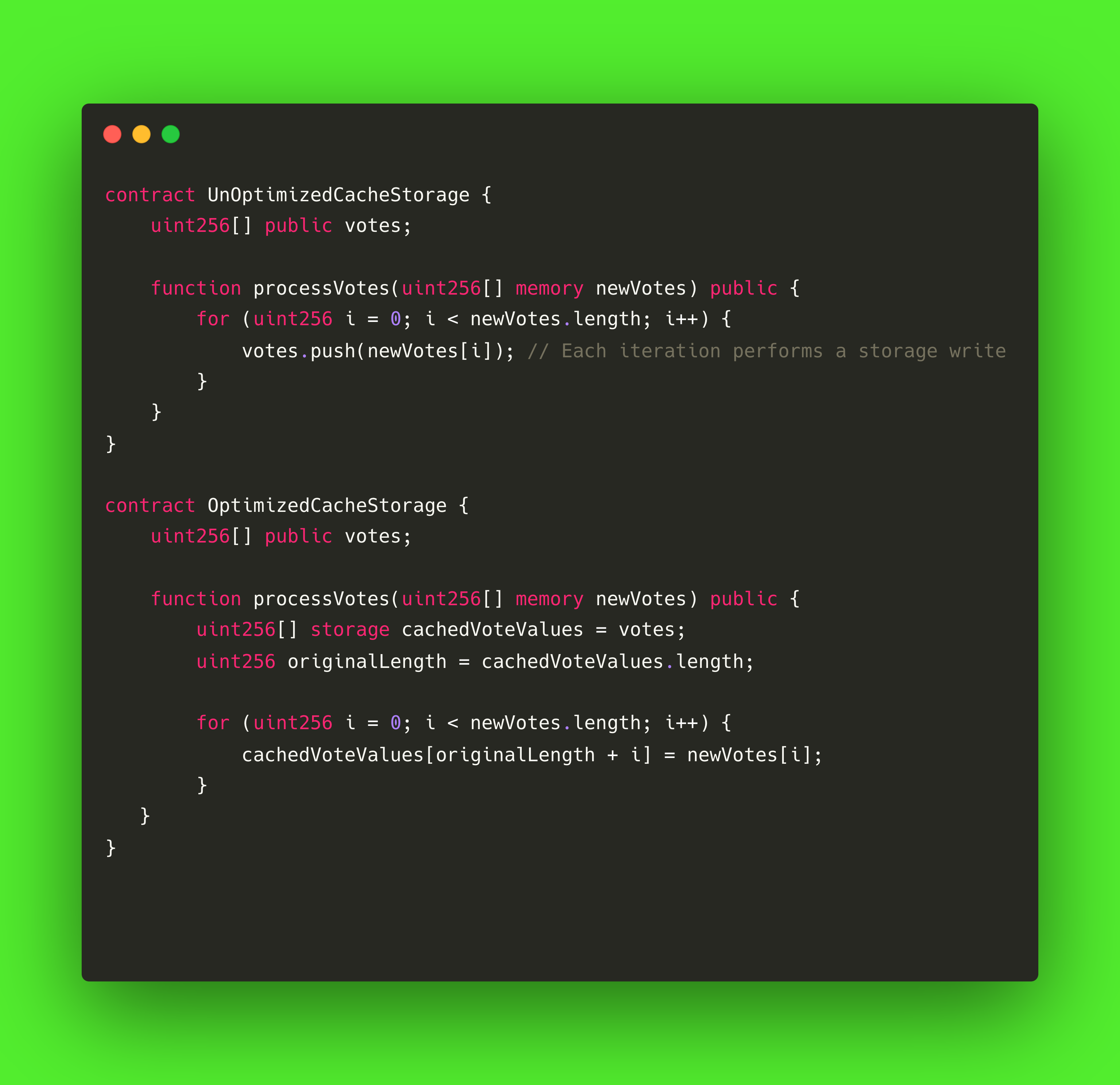
除了变量在存储槽中的布局外,了解与访问和修改存储相关的气体成本也很重要。
Kaia 虚拟机上每个存储插槽的成本: 初始化(首次写入)需要 20,000 加仑 更新(后续写入)需要 5,000 加仑 因此,尽量减少直接读取和写入存储空间的次数至关重要,尤其是在频繁调用的函数中。 一种有效的模式是,当需要在函数中多次访问存储变量时,将其缓存到内存中。
让我们来看看下面这个例子:
避免将变量初始化为默认值
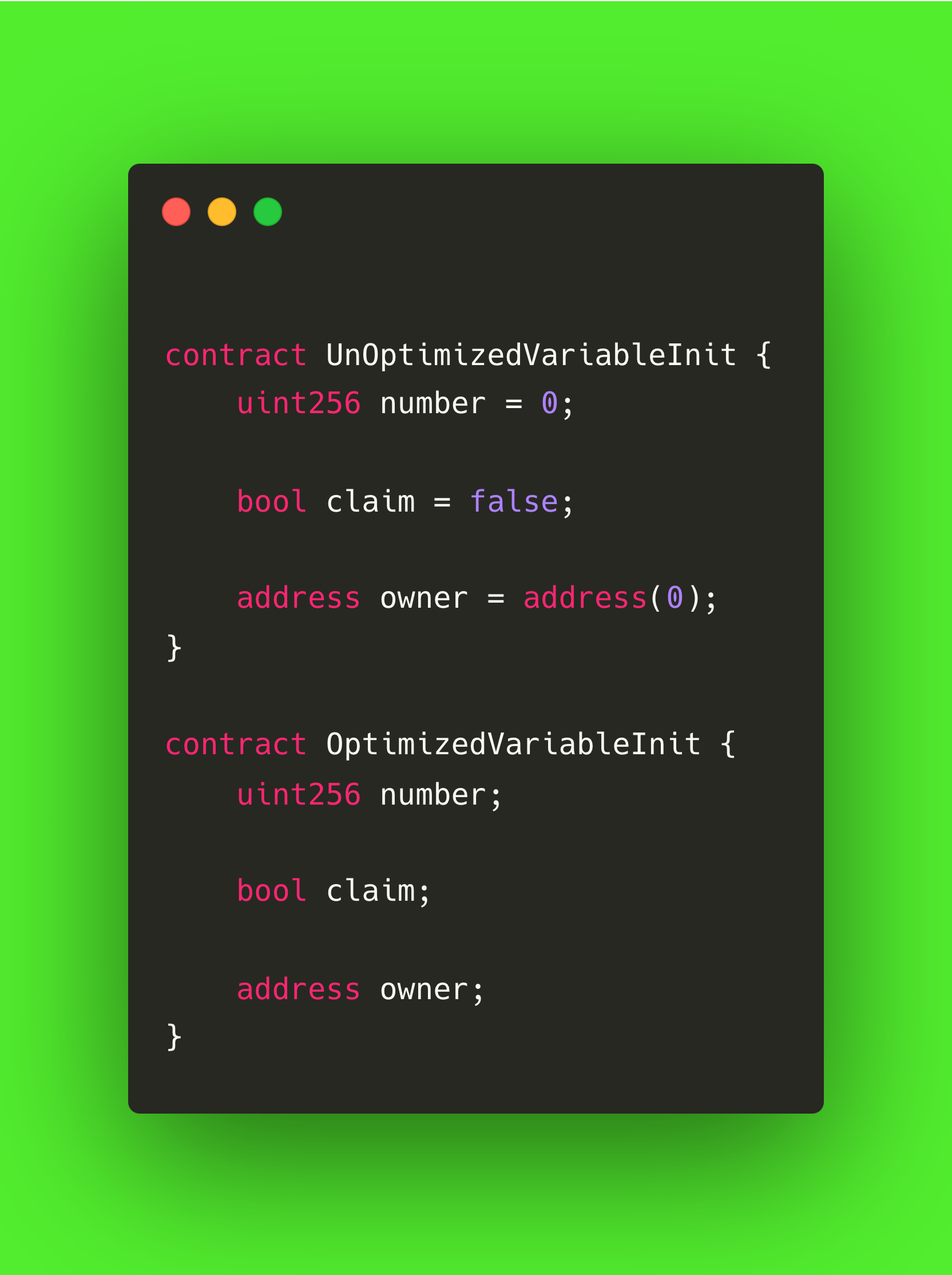
在 Solidity 中,每种数据类型都有一个预定义的默认值。 例如,address 默认为 address(0),bool 默认为 false,uint 默认为 0。 如果开发人员在变量声明时明确指定这些默认值,例如写入 bool isActive = false 或 uint total = 0,就会出现常见的低效情况。
虽然这在功能上是正确的,但在部署过程中会带来不必要的气体成本,因为 Solidity 已经默认设置了这些值。 通过声明状态变量而不赋值,可以减少合约字节码的大小,避免额外的存储操作。 这一小小的调整有助于提高智能合约的效率,使其更易于维护,尤其是在处理多个变量时。
请看下面的例子:
最小化链上数据
我们清楚地知道,交易的大部分气体成本都来自于合同存储中的数据。 最好经常询问哪些数据需要存储在链上或链下,并考虑这两种选择的利弊。 我们可以从完全链上 NFT 的案例中看到这一点,以及与传统的链下元数据 NFT 相比,它们有多么昂贵。 这意味着,通过在链外存储信息,你可以大大减少智能合约的耗气量,这只是因为你分配给存储的变量较少。
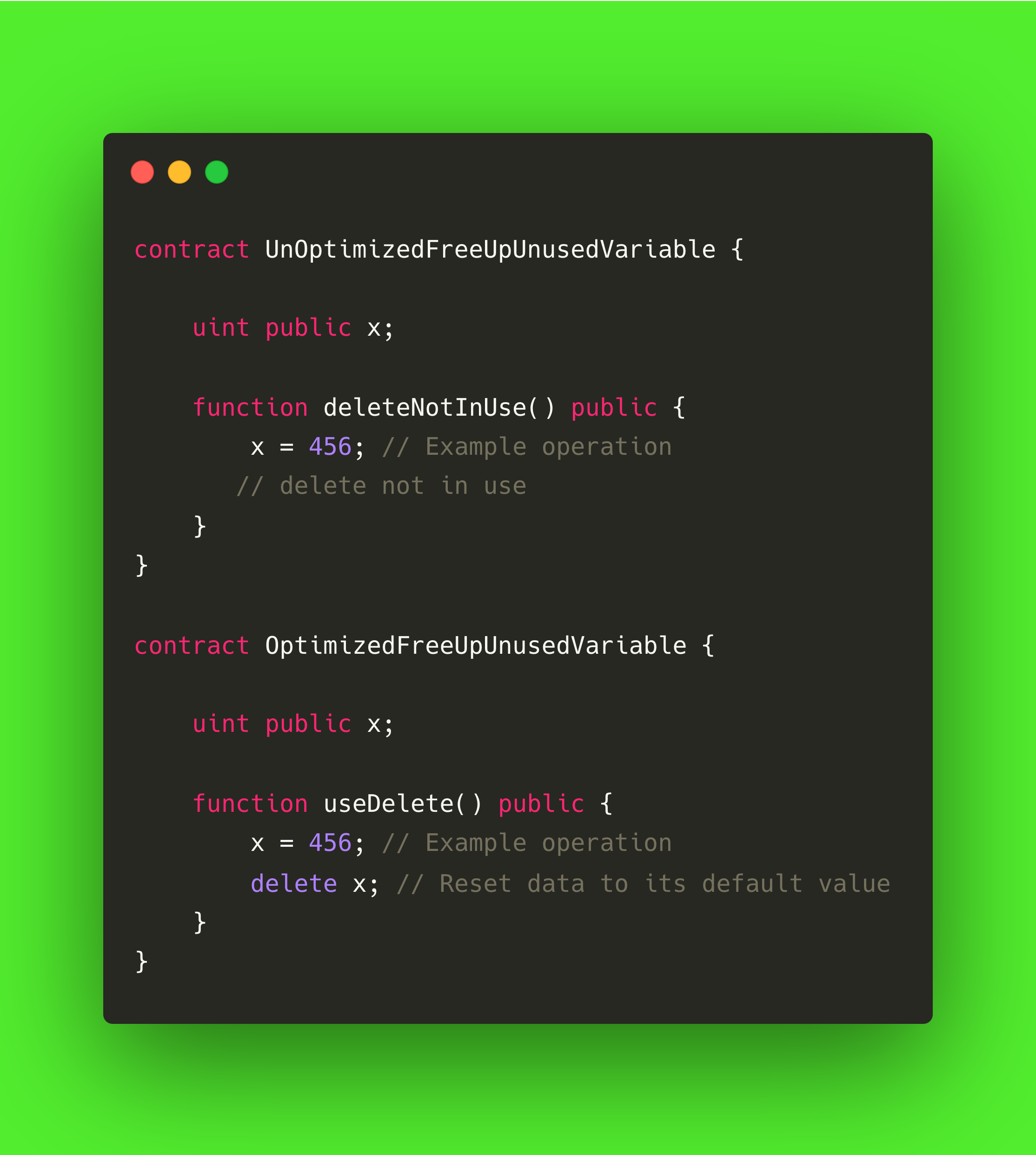
释放闲置存储空间
有时,我们会忘记释放合同中未使用的数据,这无形中有时会增加燃气成本,也会导致网络膨胀。 无论如何,释放未使用的存储空间非常简单,只要确定不再使用该存储空间,就可以将其值设置为 0。 您还可以使用 solidity 中的特殊关键字 delete 来释放任何数据类型。
请看下面的例子:
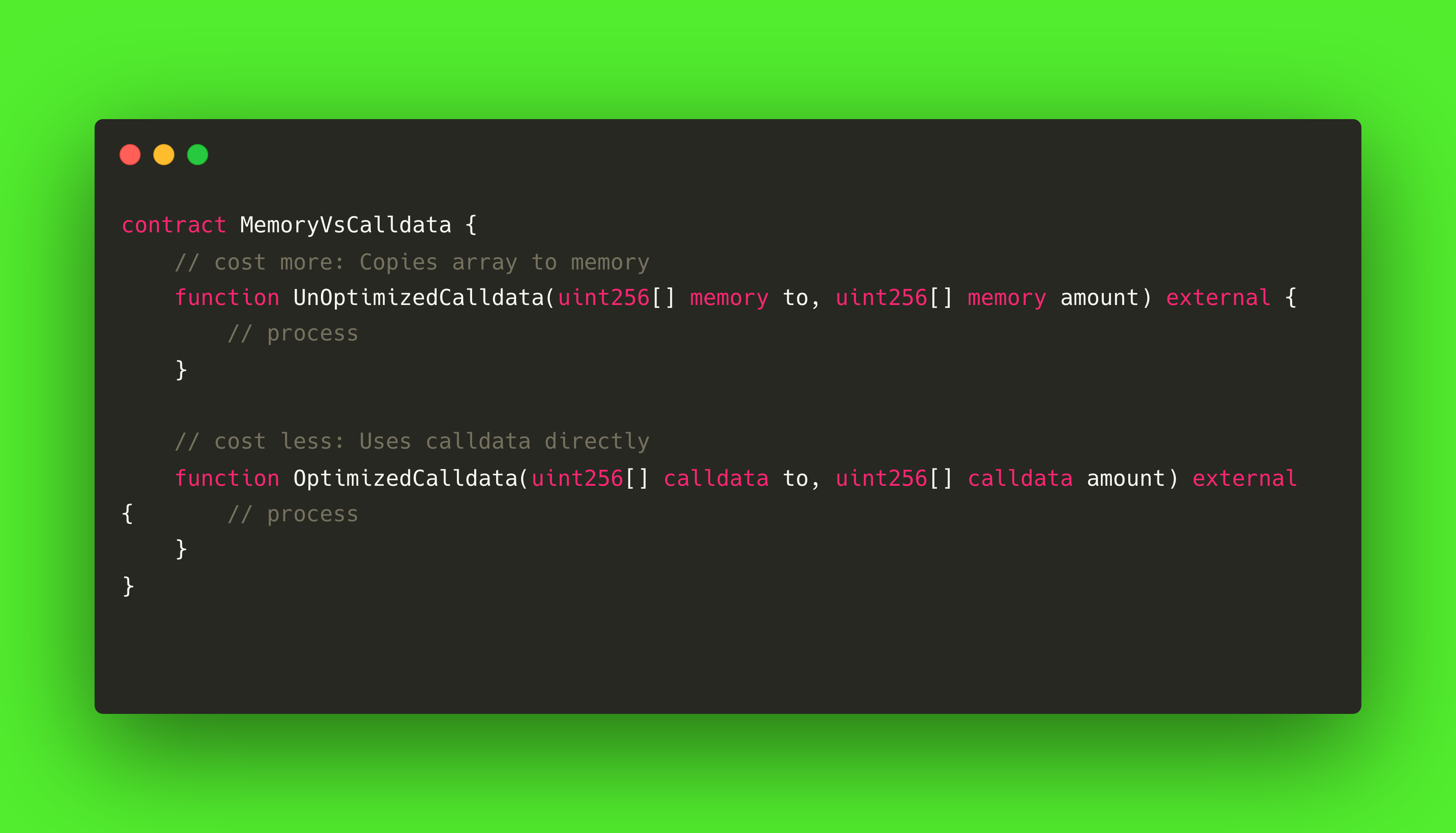
将某些函数参数的数据存储在 calldata 中,而不是内存中
在函数中使用 calldata 作为只读数组参数是一种有效的气体高尔夫技术。 Calldata 是一个不可修改、不可持久的区域,外部调用时函数参数就存储在这里。 它比内存便宜得多,因为它不涉及任何存储分配或复制。
当函数只需读取输入数组或字符串而无需修改时,将参数声明为 calldata 有助于减少气体消耗。 这对频繁调用或操作大量输入数据的功能尤其有利,例如批量传输或多收件人空投。
请看下面的例子:
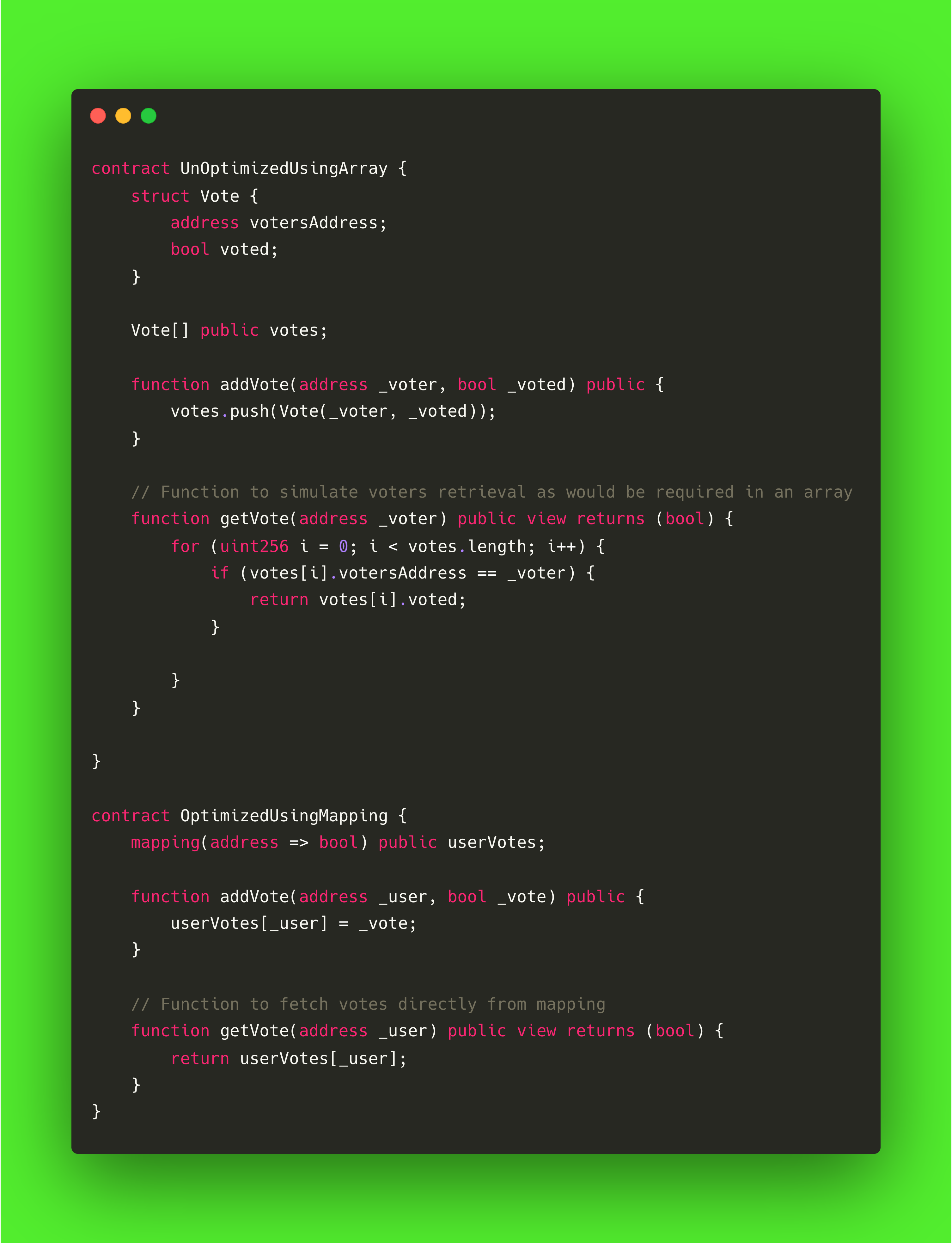
使用映射代替数组
在 Solidity 中,有两种主要的数据结构用于管理数据:数组和映射**。 数组存储项目集合,其中每个元素都分配给一个特定的索引,因此适用于有序列表。 另一方面,映射作为键值存储,允许通过唯一键直接访问值。
在处理数组时,检索一个特定值往往需要在整个集合中循环,每计算一步都会产生气体成本。 这就降低了数组的查找效率,尤其是在较大的数据集中。 除非有必要进行有序迭代或对类似项目进行分组,否则使用映射来管理数据列表会更有效率。
映射提供恒定时间访问,避免了与数组遍历相关的开销,使其成为许多智能合约优化气体使用的首选。
请看下面的例子:
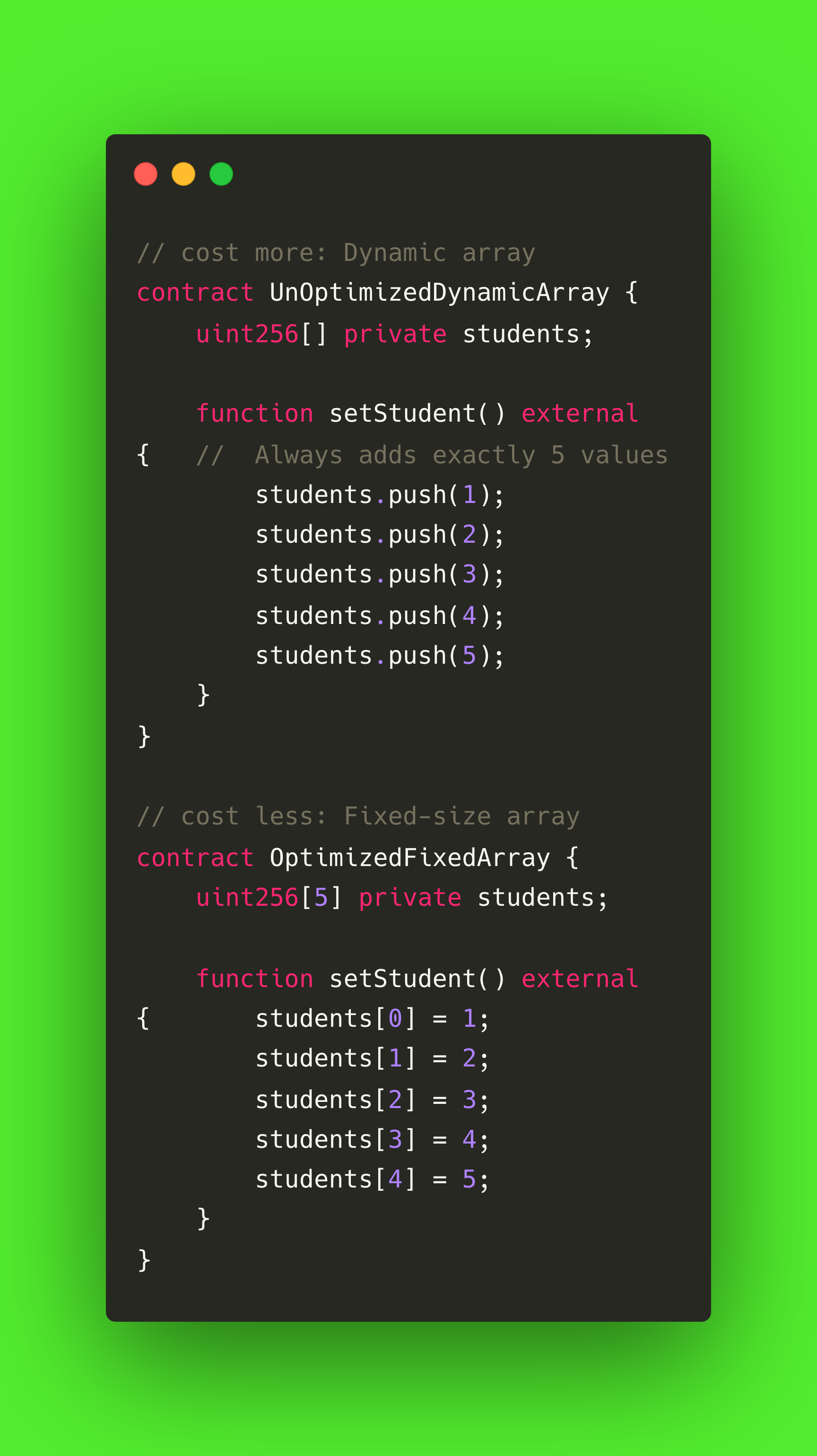
固定大小阵列优于动态阵列
虽然映射通常比数组更省气,但在某些情况下,数组也是必要的。 在这种情况下,如果在编译时就知道元素的数量,最好使用固定大小的数组。 固定大小的阵列可提供可预测的存储模式,并避免与调整大小操作相关的开销。
相比之下,动态数组的大小会在合约执行过程中不断增大,这就为内存分配和边界检查带来了额外的气体成本。 尽可能选择固定大小的阵列,有助于减少气体消耗,提高智能合约的整体性能。
让我们来看看这个例子:
使用不可变和常量
在 Solidity 中优化气体成本的有效方法是将变量声明为常量或不可变变量。 这些特殊变量类型只赋值一次,对于常量,在编译时赋值;对于不可变变量,在部署合约时赋值。 由于它们的值直接嵌入到合约的字节码中,因此无需进行存储访问,而存储访问通常是智能合约执行过程中最昂贵的操作之一。 这使它们成为在保持代码清晰度和效率的同时减少气体使用量的有力工具
让我们来看看这个例子:

优化的错误处理
在 Solidity 中优化气体时,保持简单高效也适用于错误处理。 与使用字符串信息的传统 require 语句相比,自定义错误提供了一种省油的替代方法。 基于字符串的错误存储在合约字节码中,并根据信息长度增加大小,而自定义错误则不同,它的成本要低得多。
它们的工作原理是使用一个紧凑的 4 字节选择器,该选择器来自错误签名的 keccak256 哈希值,与函数选择器的计算方法类似。 无论是在 require 还是 if 语句中使用,自定义错误都有助于减少字节码大小和运行时气体成本,同时还能在调试过程中提供清晰度。
让我们来看看这个例子:

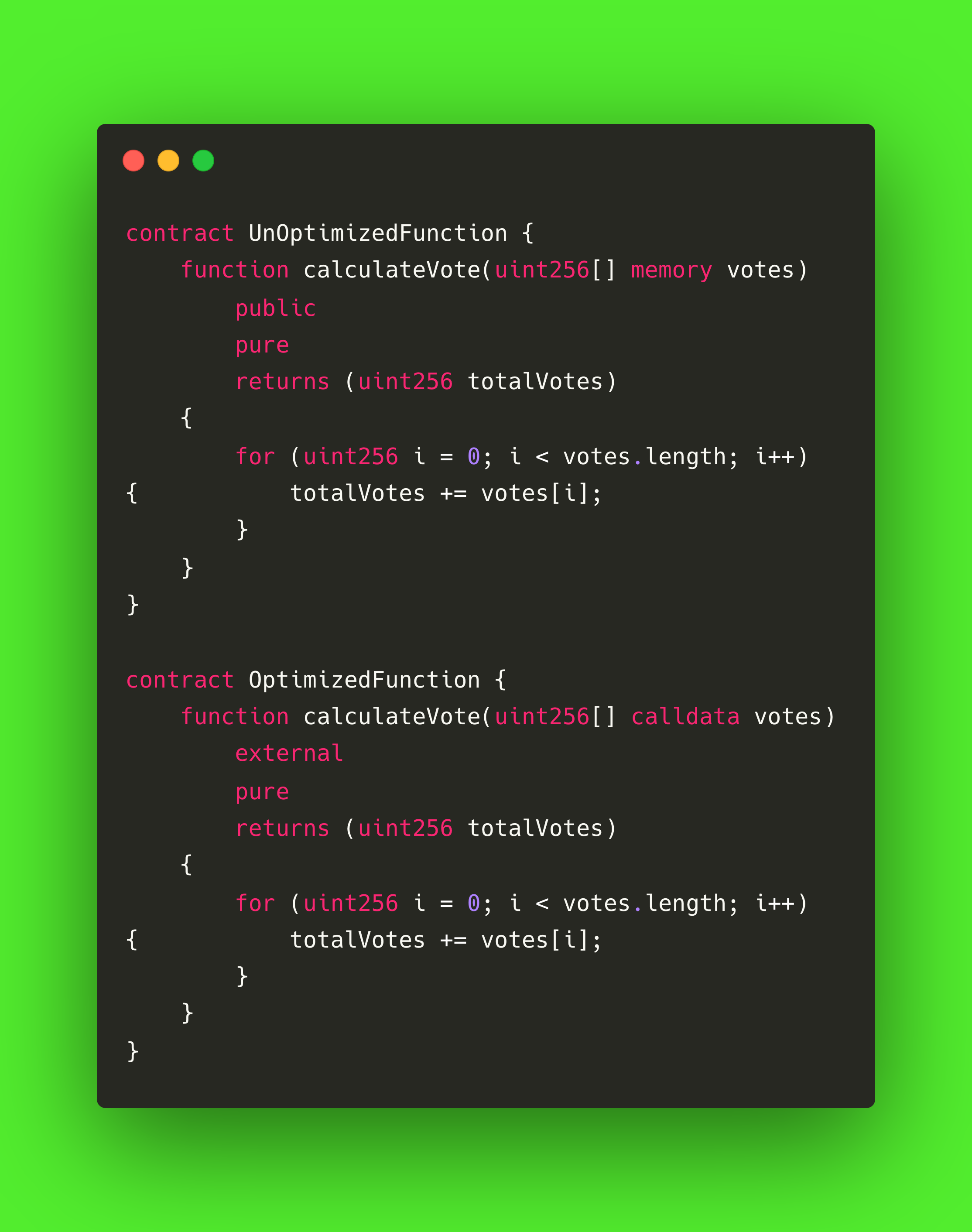
使用外部可见性修改器
当你确定一个函数只能从合约外部调用时,无论是外部拥有的账户还是其他智能合约,最好的做法是将函数的可见性声明为外部可见。 该指导基于 Solidity 如何处理函数参数和内存分配。
外部函数直接从调用数据中读取参数,调用数据是专为外部输入而优化的只读部分。 另一方面,内部和外部都可以访问公共函数。 当从合约外部调用公有函数时,它会像外部函数一样从调用数据中读取参数。
但是,在内部调用时,参数会通过内存传递,这就需要额外的内存分配和复制,因此成本较高。 将一个功能标记为外部功能,尤其是当该功能并非供内部使用时,可以减少内存操作,提高气体效率。 这一微小的变化就能带来更优化、更具成本效益的智能合约。
让我们来看看这个例子:
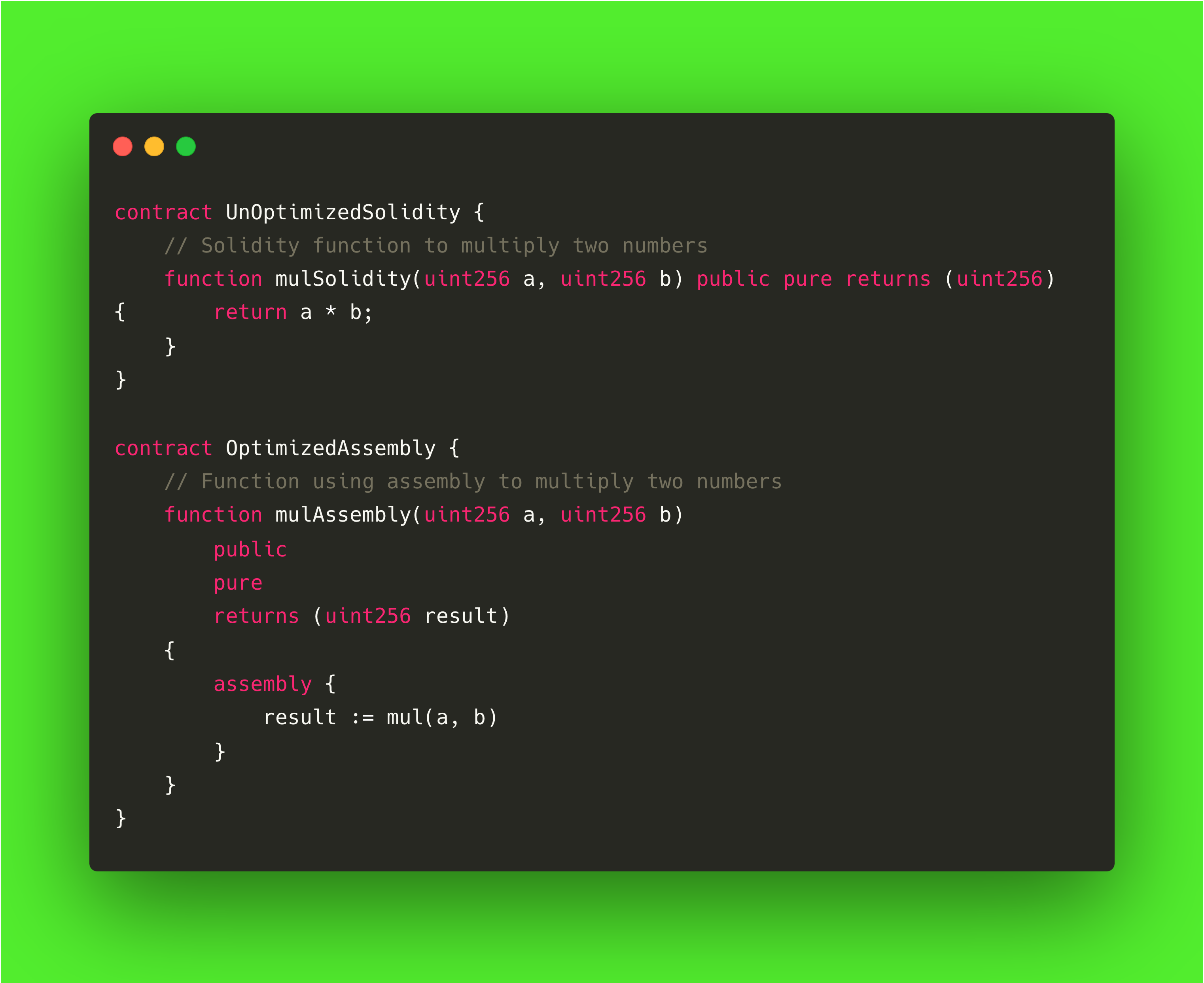
使用内联组件
内联程序集允许开发人员直接与 KVM 操作码交互。 在某些情况下,与标准 Solidity 代码相比,这种技术可以提高气体效率。 虽然它绕过了 Solidity 的安全检查并降低了可读性,但对于执行直接内存访问、位操作或自定义控制流等关键操作特别有用。 在谨慎使用的情况下,内联装配可以精确控制发动�机罩下的操作,从而帮助降低气体成本。
让我们来看看这个例子:
结论
优化气体成本是在 Solidity 中编写高效、低成本智能合约的重要组成部分。 虽然在 Kaia 上部署已为用户降低了交易成本,但开发人员仍有责任应用成熟的气体优化技术。 通过遵循本指南中概述的实践,您可以大幅降低执行成本,提高合同的可扩展性,并为用户提供更加无缝和可持续的体验。